В мае 2011 года, в расширенном докладе Майкла Рубина (Michael Rubin), занимающегося системами хранения данных в Google, прозвучал подробный сравнительный обзор современных файловых систем, в котором, кроме перечисления их преимуществ и недостатков, были даны и некоторые прогнозы о будущем развитии и потребностях информационной индустрии в этой сфере. В частности, была рассмотрена способность существующих файловых систем (ФС) адаптироваться к вызовам уже ближайшего будущего, в связи с чем, из всех были выделены четыре ведущие файловые системы "новой школы", изначально спроектированные с учетом удовлетворения самых взыскательных требований и запросов.
Майкл Рубин отдельно подчеркнул, что Google умышленно не рассматривал среди числа этих перспективных ФС, такие некогда популярные проекты, как JFS, ReiserFS, а также инновационную Tux3, – из-за их хронических проблем с графиком разработки и недостаточной поддержкой кодовой базы. Поэтому они, будучи скорее "мертвыми" чем "живыми", не позволяют рассматривать их как реальные варианты для будущей миграции. Среди всех рассмотренных вариантов, в том числе отчасти мифических (например, таких, как WinFS), были тщательно отобраны лучшие претенденты, которые уже сегодня (или в ближайшем будущем) смогут стать успешным решением для больших информационных хранилищ. Сегодня мы рассмотрим и сравним основные плюсы и минусы каждого из этих четырех претендентов, чтобы помочь сделать ваш выбор своей файловой системы будущего.
ZFS (Zettabyte File System) - одна из самых известных файловых систем, изначально созданная в Sun Microsystems для операционной системы Solaris, портирование которой на другие платформы вызвало всплеск диаметрально разных эмоций у разработчиков: от бурного восхищения и ликования, до прямо противоположного – раздражения и ярости. Попробуем ознакомиться с точкой зрения каждой из сторон, а также в причинах существования столь полярных оценок этой файловой системы. Но, прежде чем мы это сделаем, давайте хотя бы в общих чертах пройдемся по её главным отличительным особенностям и свойствам.
• 128-битная файловая система, что даёт возможность хранения практически неограниченных объёмов информации. На практике это значит, что ZFS теоретически может хранить объёмы информации, которые превышают сегодняшние технологические возможности, при условии использования текущего подхода к организации хранения данных;
• Очень большое внимание уделяется целостности и надежности хранения, как пользовательских данных, так и метаданных ФС. Для этого используются продвинутые алгоритмы хэширования всей хранящейся информации;
• Поддержка снапшотов (snapshot) и пулов хранения (storage pools), благодаря чему ZFS сочетает в себе возможности файловой системы и системы управления томами (новая концепция storage-пулов);
• Отсутствие необходимости в выполнении fsck благодаря использованию другого подхода к организации хранения данных;
• Традиционно считается, что ZFS – это достаточно производительная файловая система. Это утверждение иногда ставится под сомнение, как минимум, конкретные цифры очень сильно зависят типа задачи, на которой производится подобное сравнительное тестирование производительности;
• Прозрачные возможности избирательного сжатия и шифрования файлов;
• Поддержка автоматического распознавания и объединения (исключения) файлов-дубликатов;
• ZFS не поддерживает квоты. Вернее сказать, её поддержка квот несколько своеобразна: понятие "выделение квоты" значит в терминологии ZFS то, что вы ограничиваете размер создаваемой файловой системы. Дизайн системе таков, что каждому пользователю ZFS следует выделять свою собственную файловую систему со всеми сопутствующими ограничениями;
• Определенные проблемы создает нетехническая особенность ФС - несовместимая с GPL лицензия на код;
• И многое-многое другое, т.к повторюсь – ZFS чрезвычайно велик в своих возможностях и особенностях, и перечислить всех их здесь просто не представляется возможным.
Конечно, если смотреть на эти возможности по отдельности, то они во многом не новы и встречаются в том или ином виде в различных других файловых системах, но такой единый комплекс из приведенных возможностей впервые представлен только в ZFS, что и делает её столь уникальной и интересной на данный момент. Если добавить её относительно зрелый возраст и очень хорошее состояние в плане стабильности кода – становятся понятны те бури эмоций, которые она вызывает в широких кругах юниксоидов.
Что касается резко отрицательных откликов на эту, вне всяких сомнений, уже знаменитую файловую систему, то они сводятся в основном к следующим тезисам. Один из ведущих разработчиков Linux, кстати, ответственный за поддержку её дисковой подсистемы, Андрей Мортан (Andrew Morton), разразился гневными обличениями ZFS в "чудовищном нарушении уровней реализации". Группа других разработчиков Linux присоединилась к его обвинениям в "жутком дизайне" ZFS, и на данный момент можно констатировать, что язвительные выражения Андрея Мортана в адрес ZFS - "rampant layering violation" и "unmaintainable mess" - стали уже своего рода интернет-мемами, на которые заочно уже попытались ответить многие разработчики из Oracle, Linux, RedHat, FreeBSD и других известных проектов.
В качества ответа на эти выпады, процитирую только ведущего разработчика ZFS Джефа Бонвика (Jeff Bonwick): "Все эти обвинения в нарушении дизайна уровней реализации, оттого, что ZFS комбинирует в себе сразу функциональность файловой системы, менеджера томов и RAID-контроллера. Я полагаю, что ответ на эту претензию зависит от того, что понимать под обвинением "нарушает дизайн". В процессе разработки ZFS мы установили, что стандартный дизайн абстрагированных уровней дискового стека провоцирует удивительное количество ненужной сложности и избыточной логики. В процессе рефакторинга мы пришли к мнению, что решение проблемы – это пересмотр границ слоев и их отношений, - что делает все сразу намного более простым." Какую бы позицию в отношении ZFS не занимали лично вы, следует признать как минимум одно: ZFS - это принципиально новая технология в индустрии файловых систем
На сегодняшний день просто не существует другой такой файловой системы, которая одновременно включала бы в себя такое фантастическое нагромождение возможностей, которое уже реализовано в ZFS. Этот подход прямо противоречит хорошо известному принципу KISS (http://en.wikipedia.org/wiki/KISS_principle), и создание подобных крупных комплексных систем характерно, скорее, для мира Windows, но никак не является проявлением принципов знаменитого unixway, где деление всего и вся на атомарные и независимые функции и операции является священным.
Новейшая файловая система, которая в данный момент очень активно развивается, и, несмотря на ещё несколько незрелый вид, уже интегрирована в ядро ОС Linux. В целом, говоря предельно кратко, Btrfs – это файловая система, созданная специально для Linux, основанная на структурах B-деревьев и работающая по принципу "копирование при записи" (copy-on-write).
Мне кажется, что для понимания необходимости создания этой файловой системы, необходимо хотя бы вкратце показать исторический фон, на котором она создавалась. В связи с этим стало уже стереотипным мнением, воспринимать Btrfs как прямой ответ на файловую систему ZFS, которую было запрещено включать в состав ядра Linux из-за лицензионной несовместимости с ним. Феномен появления столь масштабного решения как ZFS, ряд возможностей которой отсутствовали в традиционных файловых системах Linux, нельзя было оставить незамеченным, поэтому Крис Мэйсон (Chris Mason), директор управления Linux Kernel Engineering в Oracle, инициировал разработку новой, не менее масштабной и амбициозной ФС, основанной c прицелом специально под ОС Linux.
В заключение нашего небольшого исторического экскурса, следует сообщить о переломном моменте в развитии Btrfs, который произошел в конце 2007 года, когда на совместном совещании ведущих разработчиков Linux из компаний Oracle, Red Hat, Novell, IBM, HP, Intel, посвященного созданию файловой системы нового поколения для Linux (Next Generation FileSystem, NGFS), было принято решение сделать ставку на совместное развитие btrfs, как наиболее универсальную и отвечающую всем современным вызовам ФС. После этого решения Btrfs получила уже официальный статус NGFS для Linux, что усилило её дальнейшее развитие, превратив в эпицентр инноваций в этой области.
Прежде чем привести список основных технических возможностей этой файловой системы, следует ещё раз подчеркнуть, что разработка этой ФС ещё в самом разгаре, и, не смотря на то, что многое уже сделано – многие возможности ещё далеки от совершенства и логического завершения. Как пример такой незавершенности, можно привести то, что до сих пор не создан инструмент для проверки файловой системы и исправления её ошибок. Вот её основные особенности:
• Динамическое выделение индексных дескрипторов (динамические иноды, dynamic inodes). Иначе говоря, в этой ФС нет максимального количества обслуживаемых файлов;
• Снимки файловой системы (snapshots), а также возможности делать снимки снимков и записываемые снимки (writeable snapshots);
• Для продвинутого контроля целостности, применяются хеши на все данные и метаданные (тут нужно сразу заметить, так как от сравнения Btrfs и ZFS никак не уйти, что на данный момент в Btrfs применяется CRC-32C, что существенно хуже, чем в ZFS);
• Очень полезная возможность миграции с традиционных файловых систем ext3/ext4, что дает возможность очень прозрачного перехода на новую ФС;
• Завершаются работы над поддержкой автоматического распознавания и объединения дубликатов (дедупликация);
• Проверка файловой системы в рабочем режиме (online) и очень быстрая проверка в нерабочем режиме (offline);
• Прозрачные возможности избирательного сжатия файлов;
• Поддержка режима работы как RAID-массива (одна файловая система на нескольких томах);
• Подтома (subvolumes) и эффективное клонирование файловой системы, быстрое создание инкрементальных архивов;
• Прямая поддержка Device-mapper - важного компонента ядра Linux, с помощью которого организуется расширенное управление логическими томами;
• И многое другое.
И хотя эта ФС пока активно развивается, в качестве иллюстрации точек её будущего роста и масштабности общей задумки, в качестве примера можно привести решение компании Oracle реализовать сетевой протокол файловой системы CRFS (фактически заменяющий устаревшие NFS и CIFS), который будет спроектирован и оптимизирован полностью под btrfs. Второй похожий пример: после долгого анализа существующих ФС, консорциум Intel и Nokia выбрал для своей будущей совместной мобильной Linux-платформы MeeGo как раз btrfs, которая в сравнении с другими аналогами оказалась наиболее перспективной.
Hammer – это 64-битная кластерная файловая система, построенная на B-деревьях, созданная специально для своего проекта DragonFly BSD известным гуру из FreeBSD Project, - Мэттью Диллоном (Matthew Dillon).
Давайте перечислим основные возможности Hammer, которые доступны уже на данный момент (или реализация которых близка к завершению):
• Hammer – это файловая система, доступная немедленно даже после падения и перезагрузки системы, здесь нет fsck.
• Размер ФС Hammer может достигать размера до 1 экзабайта (1 миллиард гигабайт), при этом вмещать в себя до 256 томов, каждый из которых может достигать размера до 4 петабайт (4096 терабайт).
• Возможность отката любой дисковой операции и возврата состояния ФС в определенную точку.
• Метод крупнозернистой истории реализуется через мгновенные снимки ФС (снапшоты). По умолчанию системный крон генерирует один снапшот в день, который хранится в течение 60 дней. Количество и частота снапшотов не ограничена. Все хранимые снапшоты индексируются также посредством B-дерева таким образом, чтобы сделать их хранение на носителях максимально эффективным. Каждый отдельный снапшот полностью отражает состояние файловой системы в заданный промежуток времени. Параллельный метод мелкозернистой истории фиксирует все системные операции в пределах около 20-60 секунд, которые также доступны для отката или повтора (undo/redo options), а также их анализа в случае любого сбоя (мелкозернистая история используется, чтобы избежать избыточных и ресурсоемких операций, характерных для снапшотов, при этом не теряя непрерывного контроля за системой).
• Возможность инкрементального зеркалирования без использования очередей операций, поддержка режима "один master и много slave".
• Заканчивается тестирование работы в multi-master режиме с распределением данных на несколько хостов сети (резервирование за счет дублирования данных на разные машины). Также реализована поддержка асинхронных транзакций.
• Возможности для создания псевдо-файловой системы (PFS) внутри файловой системы Hammer. Можно создать до 65.535 таких файловых систем. Каждая PFS задействует независимое пространство нумерации inode'ов, что позволяет использовать ее в качестве источника или цели репликации.
• Реализована система контроля максимально эффективного распределения пропускной способности канала при выполнении множественного бэкапа ФС (или ее PFSs) на ее slave-PFSs, физически находящиеся на удаленных хостах.
• Поддержка автоматического объединения дубликатов данных на всех PFS (дедупликация).
• Из недостатков – для очистки и реблокинга ФС (pruning/reblocking ops) требуется регулярный запуск специальной сервисной задачи (она выполняется быстро, как правило, в пределах нескольких минут).
Нелишним будет еще раз подчеркнуть, что Hammer в стабильной версии доступен на данный момент лишь на своей родной DragonFly BSD (имеется экспериментальный FUSE-модуль для Linux, который позволяет работать с этой ФС в режиме read-only).
Несмотря на солидных новичков, описанных выше, также в список ФС будущего был включен и яркий представитель "старой школы", которым в полной мере является самая прогрессивная ФС 90-х годов – XFS. Хотя нужно сразу отметить, что несмотря на то, что XFS во многом проигрывает всем трем вышерассмотренным представителям "новой школы" по отдельным решениям, при этом, в общем и целом, XFS смотрится достаточно современно, вполне удовлетворяя потребности индустрии на "сегодня", тогда как вышерассмотренные ФС проектируются уже скорее исходя из вызовов "грядущего завтра".
Итак, XFS – это 64-битная высокопроизводительная журналируемая файловая система, созданная компанией Silicon Graphics, полностью основанная на уже проверенной временем технологии B-деревьев. Следуя уже привычной схеме, приведем ее типичные черты, также остановившись и на недостатках, которые отчетливо проступают по мере ее использования в современных условиях.
• Реализована поддержка очень больших файлов.
• Несмотря на то, что официально XFS везде позиционируется как настоящая 64-битная ФС, стратегия дискового драйвера реализована так, что он везде, где это только возможно, избегает использования 64-битного режима адресации, используя 32-битную адресацию, для чего активно используются AGs (allocation group, AG).
• XFS официально - журналируемая файловая система, но опять же, с той лишь оговоркой, что фиксируются лишь изменения метаданных, включая операции с суперблоком, AGs, inodes, каталогами и свободным пространством. При этом XFS вообще никак не журналирует пользовательские данные.
• Другая яркая индивидуальная особенность XFS, что эта ФС была изначально спроектирована с прицелом обеспечения максимально высокопроизводительного доступа к файловой системе, вплоть до сотен Mb/s. Для этого реализовано специальное распараллеливание I/O-запросов, активно применяется стратегия размещения файлов как можно более непрерывно, имеется отложенное выделение зон (delayed file extent allocation), реализовано многопоточное чтение-запись (по потоку на каждый экстент), используется агрессивная стратегия группировки (clustering) запросов на запись и т.д., - что в сумме очень актуально в современных условиях повсеместного распространения скоростных дисковых устройств.
• Нужно отметить ярко выраженное следствие применения механизма отложенного размещения, о котором мы упомянули выше: его эффективность прямо пропорциональна имеющейся величине оперативной памяти (RAM), что опять-таки очень выгодно при современных тенденциях развития серверного оборудования.
• Реализация журнала транзакций является самым противоречивым в устройстве XFS, так как дизайн таков, что через него проходят все изменения метаданных файловой системы.
• Слабое место XFS – скорость обработки каталогов, содержащих большое количество файлов: при таком сочетании условий сложность реализации алгоритма листинга каталогов приводит к некоторым провалам производительности этой ФС. В таком случае рекомендуется использование специальной утилиты xfs_fsr для оптимизации работы файловой систем и устранения узких мест в скорости отклика файловой системы.
И все-таки, несмотря на несколько скептическое отношение к XFS в этом обзоре, следует признать, что у этой ФС есть реальные шансы претендовать на большое будущее. Как сообщает ведущий разработчик из Red Hat Валери Орорэ (Valerie Aurora), эта крупная компания всерьез заинтересовалась XFS, пригласив к себе на работу ее трех самых активных разработчиков. Уже в 2010 году RedHat сделала более 70% всех коммитов в драйвер XFS для ядра Linux, а в 2011-2012 годах намерена продолжить серьезное развитие XFS, для достижения паритета ее возможностей с ведущими ФС "новой школы".
Интересно также, что, по словам Эрика Сандина (Eric Sandeen), еще одного из разработчиков XFS в RedHat, XFS, которая традиционно считается очень сложной реализацией ФС, в процессе ее развития постепенно упрощается – что хорошо заметно даже через постепенную регрессию строк в ее Linux-драйвере, тогда как те же btrfs и ext4 демонстрируют взрывной рост сложности по мере своего развития. Этот же разработчик отмечает, что если дополнительно учесть очень тщательное комментирование XFS (примерно 40% всех строк в исходниках драйвера – это комментарии к коду), то раздувание и усложнение кодовой базы btrfs будет даже еще большим (против 17% комментариев соответственно).
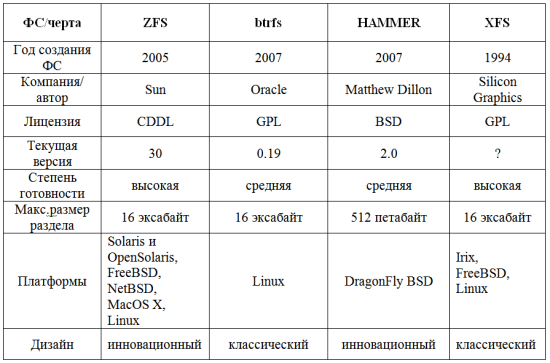
Ну что ж, ознакомившись с наиболее перспективными файловыми системами ближайшего будущего по версии экспертов Google, попробуем определиться и сделать свой выбор, чтобы как следует подготовиться, как выразился вышеупомянутый разработчик из Google, к приходу "Эпохи Больших Данных". Для удобства я свел все общие данные о рассмотренных нами ФС в таблицу.
И нашу практическую часть обзора предлагаю начать с XFS. Эта файловая система очень хорошо масштабируется, она уже сейчас способна оперировать огромными объемами данных. Большая скорость ввода-вывода – конек этой файловой системы. Дополнительным условием эффективности XFS является наличие качественного питания (внезапные отключения достаточно неприятны для нее) и больших объемов оперативной памяти на сервере, что позволяет раскрыть весь потенциал механизма отложенного размещения и прочих "ленивых" техник, обильно реализованных в XFS. Сильная многопользовательская нагрузка на хранилище позволяет продемонстрировать XFS свой инновационный механизм параллельной записи и низкую ресурсоемкость.
При этом важно понимать, что идеала не существует, и узким местом именно этой ФС являются операции над большим количеством мелких файлов или удаление развесистых деревьев каталогов - в этом случае вы вряд ли увидите ту производительность, на которую рассчитывали. Если не считать большой проблемой невозможность уменьшить размер уже созданной ФС – вот, пожалуй, и все узкие места этой надежной и уже проверенной временем файловой системы. Что касается конкретных реализаций, то XFS прекрасно чувствует себя как на Linux, так и на FreeBSD, поэтому выбрать платформу для хранилища здесь есть из чего.
Что же касается ZFS, то первое что приходит на ум, это параноидальное недоверие этой ФС к железу, когда контроль за целостностью данных носит многоуровневый и чрезвычайно изощренный характер. Здесь невольно вспоминается, что на заре SATA, когда первые диски с этим интерфейсом выпускались с большим количеством брака, порождая проклятия особенно со стороны обладателей ext2, разработчиков ZFS на многих конференциях можно было увидеть в майках с мессианской надписью "ZFS любит SATA", они как бы подчеркивали, что эта ФС способна позаботиться о вверенных ей данных, даже если само "железо" не всегда способствует этому. Поэтому, если у вас в серверной обилие дешевого железа, или ваши серверы хранят просто бесценные данные (или, для наибольшей изощренности, и то и другое вместе) – ZFS будет очень удачным выбором.
С другой стороны – степень масштабируемости системы под ZFS просто безгранична. Если учесть скорость ее работы, как правило выше среднего, и огромный выбор и гибкость настроек (добавьте сюда родной менеджер томов и программный RAID-контроллер) – это, пожалуй, идеальный выбор для создания больших хранилищ данных. И если последнее утверждение можно смело отнести к Solaris/FreeBSD, то в отношении Linux нужно сделать отдельную важную оговорку.
ZFS не была включена в ядро Linux из-за патентных ограничений, и чтобы обойти это, был собран FUSE-модуль для поддержки этой ФС в Linux на пользовательском уровне. Конечно, потери скорости и стабильности работы в таком варианте ФС огромны. Но, к счастью, существует как минимум два сторонних решения, где поддержка ZFS реализована все-таки на уровне ядра в качестве самостоятельного модуля. Это, прежде всего, Native ZFS во главе с Брайаном Белендорфом (проект финансируется Министерством энергетики США). Во-вторых, альтернативный, но такой же открытый и бесплатный вариант от индийской компании KQ Infotech. Лично я рекомендую остановиться на последнем варианте, так как это более качественная и полная реализация ZFS для Linux (дополнительно обеспечена поддержка ZFS POSIX Layer). Но, в обоих случаях, несмотря на все озвученные плюсы, ZFS все-таки не самый сильный выбор для Linux, так как вы останетесь с этим выбором наедине, лишенные поддержки со стороны официальных разработчиков ядра, тем более если учесть скорое пришествие Btrfs…
Кстати, о Btrfs. Имеет смысл рассматривать эту ФС пока применительно только к ОС Linux (то же самое можно сказать и о Hammer к DragonFlyBSD), и можно определенно сказать, что через годик-другой это будет наиболее универсальный и взвешенный выбор для этой ОС из всех возможных. А пока… эта файловая система отлаживается, расширяется, растет и активно проходит фазу становления, необходимую для ее окончательного взросления. По словам ее ведущего разработчика, переход на эту ФС в качестве основной для Linux запланирован на 2013 год.
Заключение
Возвращусь к примеру, с которого мы начали эту статью, где докладчик Майкл Рубин в качестве примера выбора ФС сообщил, что Google на данный момент использует на своих Linux-серверах ФС ext4 с полностью отключенным журналированием, полагаясь на аппаратные решения для сохранения целостности своих данных. Как оказалось, в стандартной конфигурации ext4 операции журналирования понижали производительность системы на 23-35% в зависимости от типа журнала, что оказалось в итоге неприемлемым для поискового гиганта. "Поэтому выбор системы, ее режим работы и даже оборудование для ее реализации – задача сугубо индивидуальная. При этом важно всегда смотреть вперед и не забывать про перспективу: ext4 позволяет провести прозрачную миграцию на Btrfs, поэтому мы остановились именно на ней", – объясняет стратегический выбор своей компании Майкл Рубин.
При создании собственного сайта его владельца ожидает ряд расходов, один из которых связан с оплатой хостинга. Дорогой хостинг считается оптимальным решением для профессиональных, крупных или ресурсоемких сайтов. Если же проект является пробным, ...
Давайте представим, что вы управляете собственным отделом продаж, в основе которого лежат телефонные звонки, встречи и письма. История общения хранится в одной базе, чтобы находить новые лиды и выстраивать плодотворное сотрудничество. Поэтому ...
По каким-либо причинам у разработчика или владельца сайта может возникнуть необходимость осуществления переноса проекта на новый хостинг. При этом важно понимать, что проведение такого мероприятия – довольно непростая задача, требующая не только ...
Технически подготовленная структура сайта не гарантирует его коммерческую рентабельность. Важно учитывать массу сторонних критериев, в том числе поведенческие факторы потенциальных пользователей. Задача веб-дизайнера создать такой макет, который ...
Чтобы обеспечить существование и прогрессивное процветание любой современной компании, требуется использовать современное оборудование. Ни один человек, ни одна организация не может обойтись без использования интернета. Для связи между сотрудниками ...
Сейчас социальные сети буквально «заполонили» весь мир. Появилось их огромное количество, что позволяет расширить функциональные возможности ведения бизнеса, получать огромное количество прибыли в виде денежных средств и зарабатывать положительную ...
Только профессиональные IT-специалисты знают, как эффективно «продвинуть» свой интернет-ресурс во Всемирной паутине. Они применяют современные способы, в том числе продвижение сайтов посредством грамотного подбора ключевых слов, создания ...
Надежный VDS, залог успешного функционирования вашего портала в интернете Интернет технологии не стоят на месте и с каждым годом они выходят на новый качественный уровень, предоставляя практически неограниченные возможности обычным людям по создании ...
Российская компания «Яндекс» – не только один из двух самых известных российских интернет-гигантов. Это еще и одна из наиболее быстро растущих интернет-компаний мира. Достигнув в интернет-бизнесе, казалось бы, всего желаемого, «Яндекс» не ...
Перед запуском интернет-магазина его необходимо оптимизировать. Это способствует повышению позиций сайта в выдаче поисковых систем. Кроме этого, важно усовершенствовать страницы, сделав их более удобными для каждого посетителя. Перед запуском сайта ...
Создание корпоративного сайта для какого-либо предприятия или организации преследует главным образом две цели, первая из которых позволяет привлечь новых клиентов, тогда как вторая — удержать существующих при помощи различных программ лояльности. ...
Продвижение в интернете любого сервиса должно начинаться именно с оптимизации его внутренней структуры. В противном случае все средства, вложенные в ресурс, в будущем себя не окупят. Базовая seo оптимизация сайта представляет собой список ...

 получить rss-ленту
получить rss-ленту